在 day 4 的時候,我們談到了阻抗不匹配問題,並且提到了阻抗不匹配常見的兩個形式:
有軟體開發經驗的讀者都知道:「分散式系統的種種難題也許是要到了系統長大了、必須做水平擴展 (scale out) 時才會遇到。然而,阻抗不匹配問題卻往往是在新專案開始的第一個月就會遇上了。」所以,這邊要再對阻抗不匹配問題做更詳細的討論。
阻抗不匹配早已在業界有許多前人的解法,常見的解法有兩大類:
這個作法往往在系統變複雜時,會引發嚴重的『一致性』問題。關聯式資料庫會成為資料庫的主流,主要原因之一是因為關聯式資料庫提供了單一事實來源 (single source of truth)。而文件形資料庫由於希望讓資訊模型與應用程式端一致,就勢必容易造成資料的重複儲存。當更新發生時,要怎麼寫入才能確保所有指向同一筆資料的複本都可以順利被更新到呢?
這個作法引發的問題,主要就是前述 N+1 查詢造成的效能與不一致問題。除此之外,有時候還會造成安全性問題 (SQL injection)。
導致阻抗不匹配的問題的根源,在於:『物件導向模型和關聯式資訊模型之間的概念差異。』有哪些差異呢?為了簡單,這邊先把模型帶有的概念列出關鍵的 4 項來做比較。
| 項目 | 物件導向模型 | 關聯式模型 |
|---|---|---|
| 資料結構 | 字典, 物件 | 表 (table) |
| 走訪 | 以特定的資料實體為中心,取得它的子女、鄰居 | 查詢 |
| 可組合性 | 可 | 差 (因為 SQL 是字串型態的查詢語言) |
| 語意 (semantic) | PLOP | PLOP |
在應用程式端,表示學生通常是用字典結構:
{:name "John"
:age 15
:sex "Male"}
在資料庫,表示學生通常是用資料表 (table):
CREATE TABLE student (
name VARCHAR(100),
age INT,
sex CHAR(1)
);
如果是在應用程式端,走訪的模式有概略固定的模式,通常是以某個特定資料實體,比方說,學生,為中心,從這個資料實體去找出所有與它相關的其它資料實體或是它包含的屬性。
所以,我們最常用的語句就是兩種:
- get attributes of a
- get direct links of a
另一方面,在資料庫,我們一律用 SQL 查詢來取得任何資料,也因此,我們總是必須要去描述 JOIN 、指定 JOIN 的時候使用 JOIN key,才能順利取得資料。
由於 SQL 語言是字串型態的查詢語言,可組合性很差,所以許多 ORM 都可以接受一般程式語言的輸入,根據輸入自動重組 SQL ,並且做出對應的 SQL 查詢。
可惜,這個轉換並不是容易做對的工作,ORM 的函式庫只要一不留心就會有安全性問題,比方說,SQL 注入攻擊 (SQL injection)。
讀者可能會問:「咦,這與字串型態的查詢語言有關嗎?」
問題的本質就是在於字串。合理的查詢語言設計,應該要基於資料結構的型態,參考 day 3。如果查詢語言是資料結構的型態時,我們才容易在將查詢分解成零組件時,同時確保我們分解查詢語句時的語法樹 (syntax tree) 與最後組裝起來被解釋的語法樹一致。
用白話文解釋 SQL 注入:
別人問你,用「如果」造一個句子。這個提問裡預設的語法樹長成:
「如果」 +「子句1」+ 「,」+「子句2」
你回答:「牛奶不如果汁好喝。」
這個答案的語法樹沒有「如果」…。
PLOP 語意相當抽象,這邊用實際的例子來解釋。
以下是 qsort 的兩個 Python 的實作方式,前者是傳統的命令式編程、 後者是函數式編程的作法。程式碼取自 https://rosettacode.org/。
命令式編程:
函數式編程: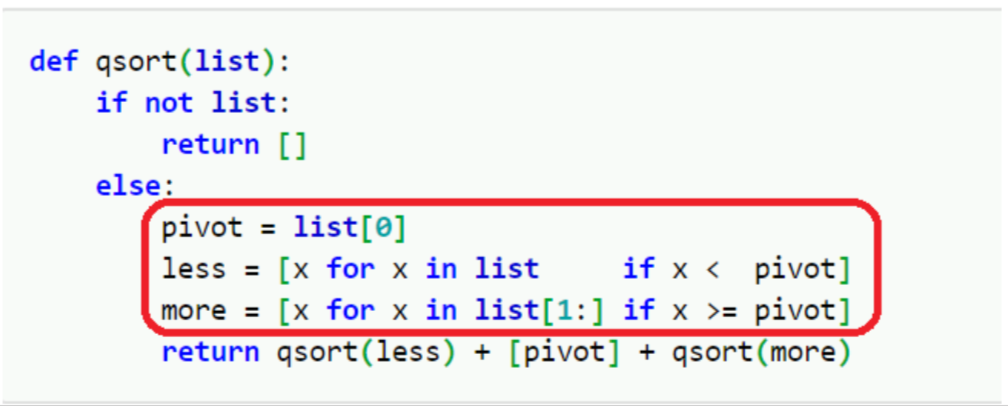
畫紅圈的部分,是功能等價的程式碼,它們的功能都是『分割陣列』:『取一個值 p,將比這個值小的全部放到 p 之前,將比這個值大的全部放到 p 之後。』。由於『分割陣列』這是一組完整的概念操作,無論我們是否將其獨立成一個專用的函數,它都是在編程的時候,要一次同時考慮、理解的操作。
第二個例子的實做方式,因為利用新配置的兩塊記憶體 less 和 more,來放置分割完成的結果,在實作上,就遠比第一個例子來得簡單。第一個例子為何複雜?因為它的實作同時處理了兩個問題:
Clojure 語言的作者 Rich Hickey 特別為了第一種編程方式取了一個名字:位址導向編程 (place-oriented programming, PLOP) ,相對而言,第二種編程方式,則可以稱之為:值導向編程 (value-oriented programming, VOP) 。對人腦而言,要透過『值』語意來編程是比要透過『位址』語意,來得簡單輕鬆得多。
而無論是「物件導向模型」或是「關聯式模型」,它對應的編程方式,都是採用 PLOP 的作法。在 PLOP 的作法,若有一個變數 A 它在 t1 時間發生了寫入,即使是在 t1 時間之前就已經包含 A 的其它變數,都勢必在 t1 之後,只能看到 t1 時間之後 A 的新值,再也無法回顧 A 變數之前的狀態。
表面上,Datomic 提供了 Pull API 與 Datalog 查詢來解決阻抗不匹配。
Datomic 的使用者如果不多細想,反正就用下去了,不知道為什麼程式寫起來很順手,怎麼憑感覺寫,都不會有 N+1 查詢的 I/O 問題,也不會遇到資料的不一致問題、也不會有安全性問題。以下,我們透過同樣的分析法來解釋這個順手的感覺。
| Datomic API | Pull API | Datalog 查詢 |
|---|---|---|
| 資料結構 | 字典 | 表 (table) |
| 走訪 | 以特定的資料實體為中心,取得它的子女、鄰居 | 查詢 |
Datomic 提供了資料結構型態的查詢語言,如此就可以確保不可能發生 SQL 注入攻擊。
Datomic 由於內建資料溯源 (event sourcing) ,對於每一次資料庫寫入,Datomic 並不會發生就地更新 (update in-place),而是將那次的寫入以事件 (event) 加以記錄。換言之,Datomic 提供的是值導向編程 (VOP) 的語意。
一旦有了值導向的語意,就可以保証「資料的不一致」不會發生。因為對於 Datomic 來說,整個資料庫在任何時間點都是對應不同的值,而且只要知道時間點,就可以加以存取對應的資料庫值,就像 git 一樣。


 iThome鐵人賽
iThome鐵人賽